




Avec la montée en puissance des ordinateurs et des serveurs, avec le souhait des utilisateurs de voir leur logiciel préféré remplir de plus en plus de fonctions, les logiciels prennent de l’embonpoint et deviennent souvent des monstres difficiles à dompter. La plupart d’entre eux conservent une architecture fermée ou monolithique.
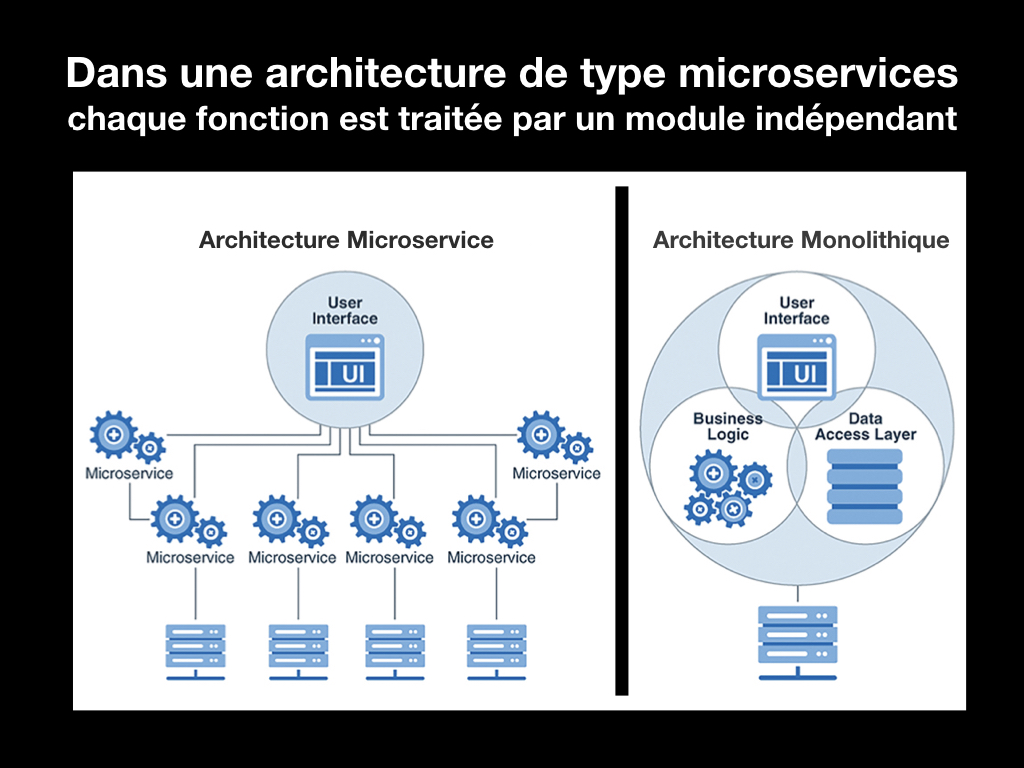
Pour assurer leur travail de manière optimale, accéder aux fonctions de base de l’OS (saisie, affichage, gestion de stockage…) et éviter de tout réécrire à chaque évolution technique, le développement de ces applications est basé sur la programmation objet. L’organisation interne du programme est découpée en modules de base qui communiquent entre eux, s’échangent les données et les états nécessaires à leur fonctionnement. Mais tout ce fonctionnement reste interne au logiciel et lui confère cette architecture monolithique.
L’enrichissement des fonctions du logiciel rend son développement encore plus lourd en augmentant le nombre de modules et, en conséquence, les échanges de données internes. Lors d’une mise à jour, il faut vérifier et valider ces échanges internes et externes vers l’OS et les drivers des divers périphériques.
Tout le monde a pesté un jour ou l’autre suite à une mise à jour de son logiciel préféré, en constatant qu’il n’est plus ou pas reconnu par l’un des périphériques ou qu’une fonction indispensable un peu complexe fait planter l’ordinateur. L’éditeur se dépêche de publier une mise à jour de la mise à jour qui, si tout se passe bien, résoudra ces dysfonctionnements et quand ça va mal en rajoute une nouvelle série. Un vrai casse-tête pour les développeurs. Cela augmente les temps de développement et exige une lourde période de tests avant la publication d’une mise à jour majeure, ce qui exige alors de recharger l’application dans son intégralité.
De l’application monolithique aux microservices
Le concept de microservice se situe dans cette lignée de la programmation objet avec l’objectif de faciliter le développement des logiciels et leur mise à jour. Les premières annonces autour de ce concept sont apparues en 2011. Il modifie largement l’architecture des applications et le travail de développement en découpant le logiciel en petits modules, mais chacun d’eux totalement indépendant et en charge d’une tâche élémentaire simple. Il n’y a plus de dépendance ni d’interaction entre eux comme dans un logiciel habituel monolithique et cela se concrétise par un protocole de dialogue sans état ou « stateless », également exploité dans la communication des navigateurs web dans les requêtes HTTP.
Une requête est envoyée par le logiciel au microservice avec tous les paramètres nécessaires. Celui-ci exécute la tâche demandée en allant chercher les ressources dont il a besoin. Une fois celle-ci exécutée, il envoie un acquittement et disparaît. Les requêtes sont adressées via des API. Comme chaque microservice est indépendant, l’applicatif peut en lancer autant que nécessaire sans devoir augmenter ses propres ressources. Cela offre des capacités d’extension à l’applicatif sans devoir le redimensionner et offre ainsi une grande scalabilité, bien sûr si l’infrastructure et les processeurs sont capables de l’encaisser.
Si un microservice ne peut pas exécuter la tâche qui lui est assignée (ressources indisponibles ou trop limitées, plantage…) l’applicatif peut en lancer un autre immédiatement sur une autre machine. Ce mode d’organisation s’adapte ainsi parfaitement aux architectures distribuées, très habituelles dans le cloud.
Comme chaque microservice est indépendant, il devient beaucoup plus simple d’effectuer une mise à jour du logiciel puisqu’il suffit de remplacer le ou les microservices dont les fonctions ont évolué. Les temps de développement sont également réduits car il n’y a plus à effectuer les vérifications liées à la validation des dépendances entre les modules internes d’une application monolithique. Ce mode de structuration permet d’intégrer facilement des microservices développés par d’autres équipes ou de reprendre des modules développés dans d’autres cadres.
Ce principe, que beaucoup comparent au Lego, modifie fortement les modes développement des logiciels en offrant à la fois, de l’agilité, de la souplesse et surtout une réactivité importante. Les plus gros services disponibles sur le web l’ont bien compris et des services comme Netflix ou Uber ont basé leur développement sur les microservices.
Dans le domaine du broadcast, Imagine Communications enrichit ses équipements avec des modules de microservices pour les piloter de l’extérieur et propose Zenium, un framework de développement basé sur les microservices. Il lui permet de développer divers workflows de production et de diffusion.
Les conteneurs, une alternative aux machines virtuelles (VM)
Un logiciel est toujours développé en liaison avec un système d’exploitation (Windows, Unix, Mac OS ou autre) qui sert à l’exploiter sur une machine avec un hardware spécifique. Il existe une grande diversité d’architectures hardware en fonction du type de processeur, de sa puissance et des interfaces servant au raccordement des périphériques. Ces éléments définissent la liste des systèmes d’exploitation (ou OS pour Operating System) pouvant tourner dessus et donc, in fine, les logiciels utilisables.
Il existe tellement de combinaisons possibles que parfois il est impossible de faire tourner un logiciel sur une machine donnée. Pour éviter une trop grande disparité du parc machines, des outils de virtualisation ont été mis au point. Leur principe est de faire tourner un OS invité (celui compatible avec le logiciel à utiliser) sur une machine hôte tournant sous un autre OS, lui compatible avec le hardware disponible.
À petite échelle, cette solution est utilisée pour faire tourner un système d’exploitation exotique, ou l’ancienne version d’un logiciel ancien incompatible avec un système d’exploitation trop récent. Les outils de virtualisation servent également à tester des logiciels avec des versions d’OS différentes sans multiplier les machines de tests. Enfin pour une DSI, cela évite une trop grande dispersion du parc machines entre une multitude de modèles d’ordinateurs.
Enfin, pour les services de cloud, la virtualisation permet d’offrir une large palette d’outils et d’OS à partir d’un parc très standardisé. Pour ces derniers, c’est aussi le moyen de faire tourner simultanément plusieurs OS ou services sur une même machine. Dans ce cas, un outil spécialisé dénommé hyperviseur va venir s’intercaler entre l’OS de la machine physique et les diverses machines virtuelles, pour assurer le bon fonctionnement de l’ensemble et répartir la charge entre les diverses machines virtuelles.
Lorsque plusieurs machines virtuelles tournent en parallèle, l’une des difficultés consiste à établir et à maintenir les liens entre les interfaces de chaque machine virtuelle (port série, USB, Ethernet, etc.) et les ports physiques de la machine hôte qui doivent être partagés entre plusieurs machines virtuelles. L’un des intérêts des machines virtuelles est aussi de les déplacer rapidement d’un serveur à l’autre en fonction des besoins du client ou de la charge des services. Dans ce cas, le maintien des liens peut devenir un vrai casse-tête et compliquer leur exploitation.
Un autre inconvénient lié à la juxtaposition de plusieurs machines virtuelles sur un même serveur consiste en la multiplication des OS présents dans chaque machine virtuelle. Chacun va s’attribuer une zone mémoire et multiplier des fonctions qui ne seront pas systématiquement exploitées. Cela conduit donc à un gaspillage des ressources. Le principe du conteneur consiste à réorganiser les éléments selon une autre architecture. Le conteneur s’appuie sur un seul OS partagé entre tous les conteneurs installés sur le serveur. Il ne renferme que l’application, les fichiers binaires et les bibliothèques associées. Le rôle de l’hyperviseur des machines virtuelles est rempli alors par le moteur de conteneurisation qui s’installe au-dessus de l’OS hôte. Il va gérer et établir les échanges entre les différents conteneurs installés et l’OS unique du serveur.
En éliminant la multiplication des OS virtuels, on gagne en efficacité et le conteneur est plus léger, ce qui permet d’installer et de faire tourner plus de conteneurs que de machines virtuelles sur un serveur. Le conteneur est également mieux protégé de toutes les interactions externes et constitue un bloc indépendant facilement transférable d’un serveur à l’autre.
L’outil de conteneurisation le plus connu est un système appelé Docker. Ses premiers développements datent de 2010-2011 et il a été réellement lancé en 2013 en tant qu’outil open source. Il est repris par de nombreux acteurs : Microsoft, Amazon, Google et IBM, entre autres.
Comme dans de nombreux débats technologiques, chaque solution présente des avantages et des inconvénients. En faveur des conteneurs, on peut citer leur légèreté, leur rapidité de lancement, leurs meilleures performances, car ils tournent directement sur l’OS de la machine et non pas à travers un OS émulé comme dans le cas des machines virtuelles. En particulier, ils sont très efficaces pour fonctionner avec des applicatifs basés sur des microservices et facilement transférables d’un serveur à l’autre.
Par contre, ils sont plus limités en termes de choix d’OS et de nombreuses applications traditionnelles ne peuvent pas être transférées dans un conteneur. Le niveau de sécurité serait moins élevé que celui offert par des machines virtuelles.
Optimiser les services de cloud avec Kubernetes
Une première approche des services de cloud pourrait laisser penser que les outils et les moyens proposés aux clients seraient une simple transposition des équipements installés chez soi sur site (ou On Premise) avec leurs unités centrales, des espaces de stockage un système d’exploitation et des applicatifs adaptés aux tâches à effectuer. Les machines virtuelles reprennent aussi ce concept.
Dans cette logique, la mise en place d’un service dans le cloud exigeait une première étape de dimensionnement d’un espace de stockage pour les données et les serveurs, la mise en place du ou des serveurs avec les machines virtuelles, l’installation des logiciels et la configuration de l’ensemble pour obtenir le service souhaité, le tout exécuté à distance. Cela demandait de multiples compétences du côté des clients et consommait beaucoup de temps.
Tous les grands acteurs du cloud se sont engagés dans un long travail de réorganisation de leur service en créant des nouveaux outils et architectures destinés à simplifier ces procédures et à optimiser la charge de leur machine.
Une première démarche a consisté à proposer des services « serverless ». Le nom pourrait laisser supposer qu’il n’y a plus de serveurs dans le cloud, ce qui est bien entendu faux. Il s’agit d’un paradigme dans lequel le fournisseur de services gère dynamiquement les ressources allouées au client et non plus à l’avance par l’utilisateur. La facturation est liée à l’usage réel et non à ses capacités prédimensionnées et souvent sous-employées. Ce mode « serverless » a permis de simplifier fortement les procédures de lancement de services dans le cloud et ainsi d’en démocratiser l’usage.
L’autre grande nouveauté est l’arrivée de la plate-forme Kubernetes (créée par Google et ensuite mise à disposition en mode libre). La fonction principale de Kubernetes est celle d’un orchestrateur de gestionnaire de conteneurs permettant d’automatiser le déploiement, la montée en charge et la mise en œuvre de conteneurs d’application sur des clusters de serveurs.
L’organisation des composants de Kubernetes est de type pyramidal avec des « nodes » et des « pods ». Un pod, l’unité de base de l’ordonnancement Kubernetes, regroupe un ou plusieurs conteneurs localisés sur une machine et dont ils partagent les ressources. Ces pods sont regroupés dans des nodes, correspondant à une machine unique. Le fonctionnement des nodes est piloté via des « kubelet » qui contrôlent le démarrage, l’état et l’arrêt des conteneurs.
Au niveau central, Kubernetes comprend un serveur d’API qui fait office d’interface interne et externe, un ordonnanceur qui gère l’utilisation des ressources sur chaque node et un gestionnaire de contrôle qui dialogue avec le serveur d’API pour créer, mettre à jour et effacer les ressources qu’ils gèrent. Les composants qui constituent Kubernetes sont conçus pour être combinés et extensibles et donc permettre de supporter une grande variété de charge de travail.
Toute la machinerie interne des services de cloud tend à disparaître à la vue du client final de manière à ce que ce dernier se consacre pleinement à la nature réelle de ses activités et à son cœur de son métier. Même s’ils sont conçus dans la perspective d’un usage dans le cloud, les microservices, les conteneurs avec Docker et l’orchestrateur Kubernetes peuvent également être déployés à bon escient sur du cloud privé, dans des data centers ou même sur des infrastructures internes sur site. Ils concernent tous les domaines d’activité IT et ne sont pas spécifiques à l’audiovisuel. Mais vu la complexité des process de diffusion d’une chaîne de TV et la lourdeur des traitements, il est évident que le secteur du broadcast est intéressé au premier chef.
Article paru pour la première fois dans Mediakwest #33, dans le cadre de notre dossier « Les nouvelles architectures des chaînes de télévision », p.54/56. Abonnez-vous à Mediakwest (5 numéros/an + 1 Hors-Série « Guide du tournage ») pour accéder, dès leur sortie, à nos articles dans leur intégralité.